R-CNN系列
本篇將會介紹以下論文:
- R-CNN (2014)
- Fast R-CNN (2015)
- SPP-Net (2014)
- Faster R-CNN (2015)
- FPN (2017)
- Mask R-CNN (2017)
- PointRend (2020) 並且會著重在最後兩篇
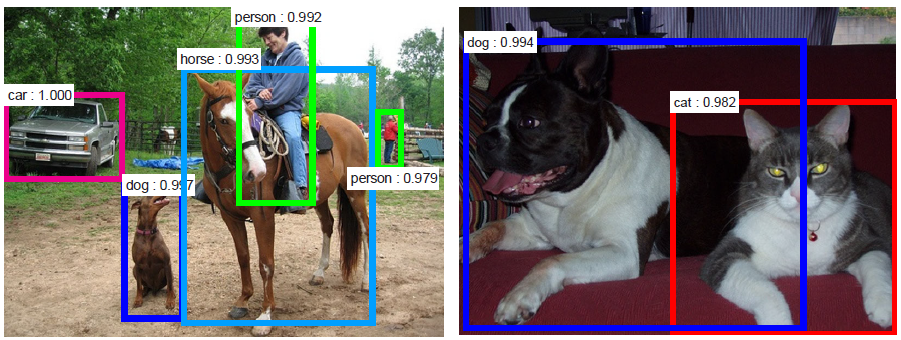
R-CNN系列主要專注在目標檢測(Object Detection)任務上,如下圖。
R-CNN [1] : Selective Search [2] + CNN (AlexNet [9]) + SVM
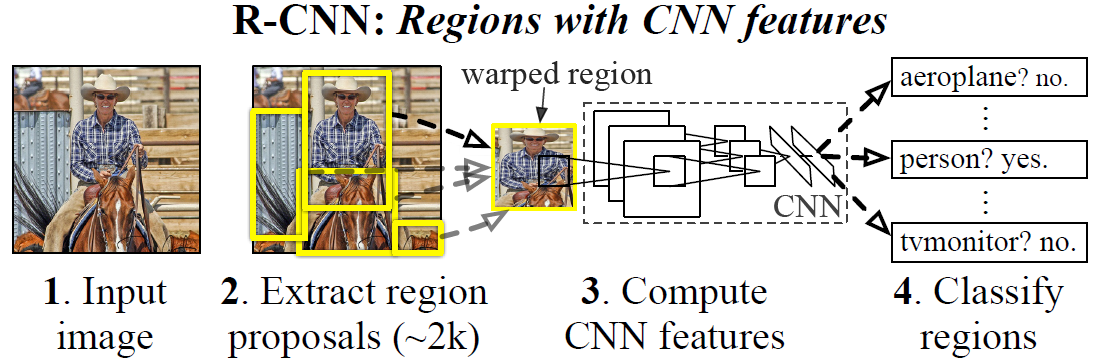
圖1 [1]
R-CNN架構:
-
輸入一個圖片
-
將圖片透過Selective Search提取出2000個候選框(Region Proposals)
-
將每個AlexNet [9]
-
將每個候選框(Region Proposals)送入CNN模型進行特徵提取
-
每個候選框(Region Proposals)都會有一組經過CNN模型所提取的特徵(features),再將特徵用SVM來進行該候選框的物體分類
候選框(Region Proposals)的特徵(features)上,使用GPU的情況下,每張圖花費了13秒;使用CPU的情況下,每張圖花費了53秒。
Fast R-CNN [3] :Selective Search [2] + RoI + CNN R-CNN擁有以下缺點: 訓練過程是多個階段進行: R-CNN的訓練過程分為三個階段微調(fine-tune)CNN模型、用於分類的SVM以及Bounding box Regression。 訓練太耗時且需要大量的存儲空間:為了訓練SVM以及Bounding box Regression,需要將每個圖中的每個物體候選框(Object Proposals)經過CNN模型提取特徵後,再將提取的特徵存入硬碟中。對於非常深的CNN模型來說,這個過程需要2.5天才能處理完VOC07訓練集中的5000筆圖像資料且需要數百GB的存儲空間。 物件偵測(Object Detection)太慢:在測試時,將從每個測試圖像中的每個物體候選框(Object Proposals)中提取特徵。使用VGG16在GPU上進行檢測每張圖需要47秒。
目前的整體架構:
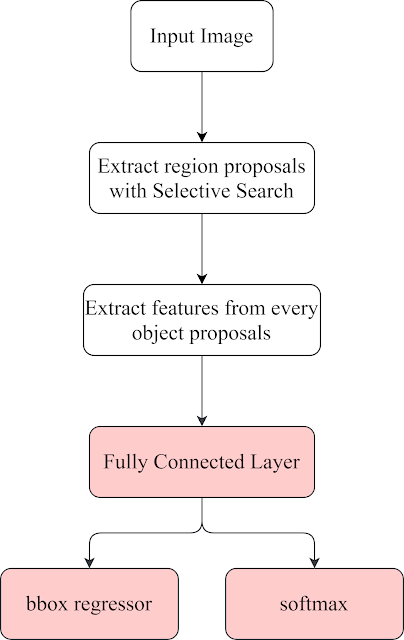
圖2
Selective Search從圖片提取出2000個候選框(Region Proposals),再將整張圖送入CNN模型進行特徵圖提取,然後將候選框透過RoI Projection投射到特徵圖上直接取得候選框對應的特徵圖,省去了將每個候選框送至CNN模型進行特徵提取的過程。
目前的整體架構:
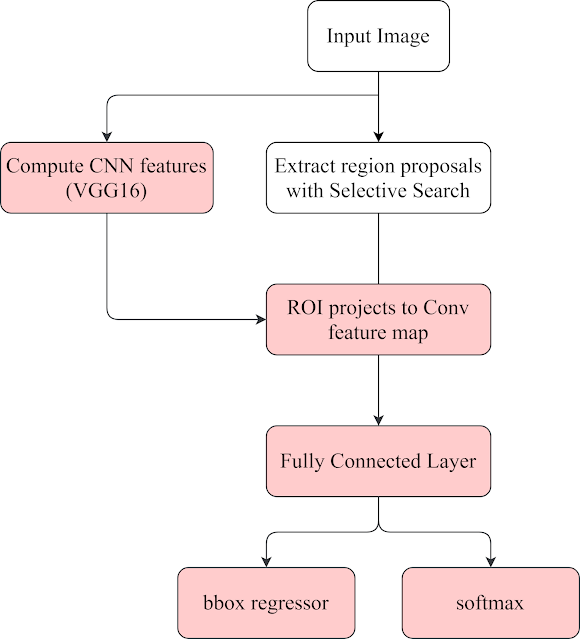
圖3
為了解決這個問題,Fast R-CNN使用到了SPP-Net [4]的技術。
Fast R-CNN
卷積層(Convolution)、池化層(pooling)、全連接層(Fully-Connected)的CNN模型中,模型的架構都是輸入圖經過縮放成固定大小的圖,然後再送入卷積層中計算出特徵圖,再將特徵圖送到全連接層,最後輸出分類結果(如下圖中上方的流程),而縮放/型變的過程多少都會損失圖像特徵;而SPP-Net的架構是在卷積層與全連接層間加入了SPP層,使得不固定大小的輸入圖可以在經過SPP層後擁有固定大小的特徵圖。
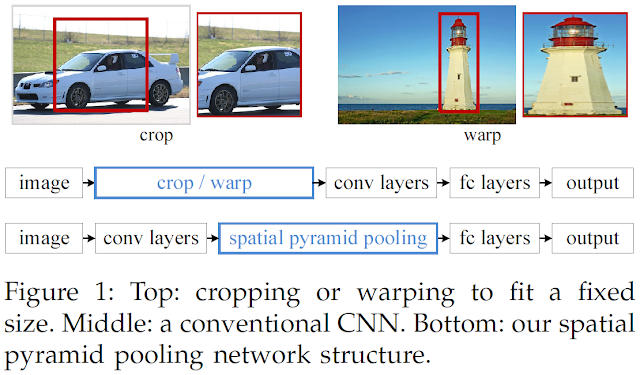
(1+4+16)x256的特徵圖。簡單來說,SPP layers是一個會依照輸入特徵圖的大小來調整max pooling參數使得輸出特徵擁有固定大小的結構。

圖6 [4]
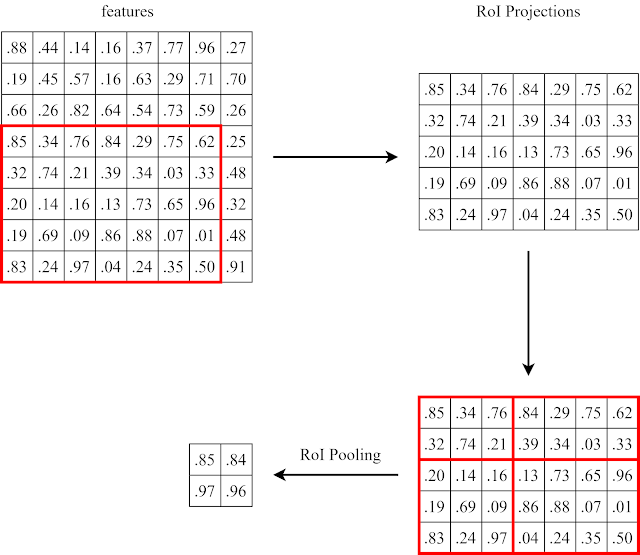
h/H x w/W大小的子網格中的值max pooling到對應的H x W網格中(整個流程如圖7所示))
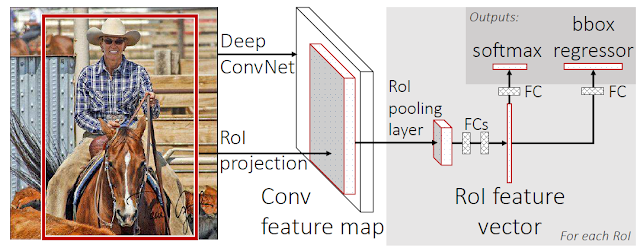
完整的Fast R-CNN架構 [3]:
Faster R-CNN [5] :CNN + RPN + RoI
儘管Fast R-CNN在各個方面都進行了優化,但是也僅能在忽略使用Selective Search尋找候選框情況下,勉強達到接近實時(near real-time)。
如果在CPU上實現Selective Search的話,每張圖像需要耗費約2秒的時間,而CNN的運算是使用GPU來實現的,Selective Search會造成整個架構在執行速度上的一個瓶頸,所以為了解決這個問題Faster R-CNN採用了一個基於GPU實現的網路模型來取代Selective Search,這個網路模型稱為Region Proposals Networks(RPN)。
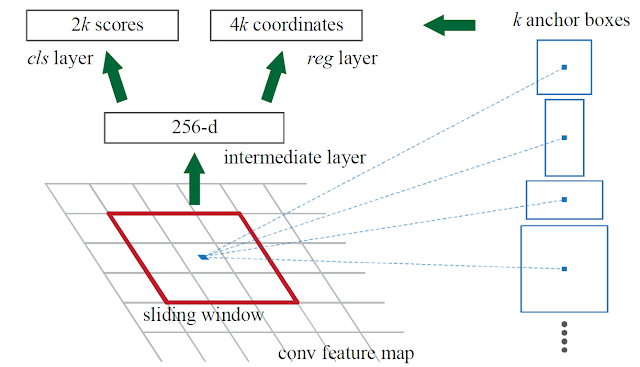
但是在捨棄Selective Search的情況下要怎麼獲得候選框呢? Faster R-CNN採用了anchors的方式來產生候選框,anchors是由三個大小(128、256、512 pixels)以及三種長寬比(1:1、1:2、2:1)所組成的,一共有9個大小、長寬各異的anchors,如圖9所示。
![]()
而anchors是在經由CNN模型計算過後的特徵圖上的每個點為中心都配置上這九個anchors(如圖10)。
60 * 40 * 9 = 21600個anchors (VGG16經過4次pool_size=2, strides=2的max pooling操作,特徵圖的大小會縮小16倍), 但是其中有的anchors會超過圖像的邊界,如果忽略超過邊界的話,大約有6千個anchors。
介紹完了anchors就可以正式進入RPN的介紹,RPN分為兩個部分: 第一部分(圖12上方部分)為分類層(box-classification layers),主要是透過softmax來分類anchors,將anchors分為positive和negative。
第二部分(圖12下方部分)為box-regression layers,負責初步的為anchors進行校正。
最後proposals layers負責綜合所有的資訊(positive anchors跟box-regression)來產生候選框
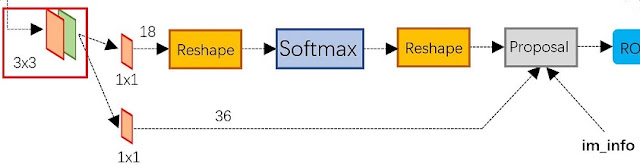
圖12 [11]
簡單的說,RPN就是在特徵圖上窮舉各個大小的anchors,再利用RPN來判斷positive、negative跟初步的anchors校正以產生出候選框。
Faster R-CNN的整體架構:
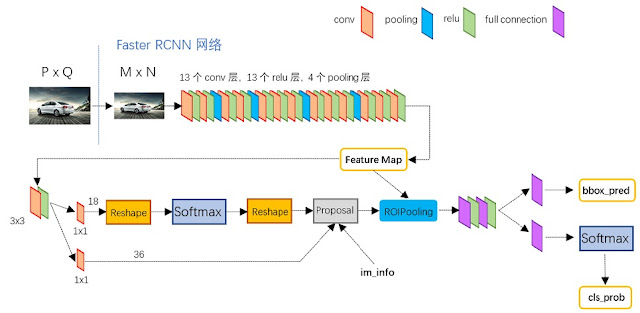
圖13 [11]
後面的架構剩RoI Pooling提取proposals的特徵圖然後進行RoI Pooling(Fast R-CNN有提到),最後輸出分類結果以及進一步的校正anchors。
Faster R-CNN採用了RPN技術達到了73.2% mAP,執行速度相比於使用Selective Search的Fast R-CNN提升了約9倍。
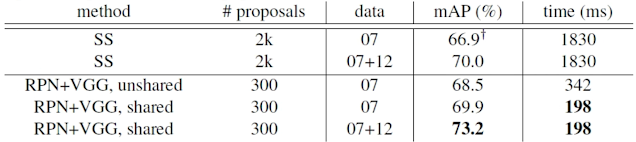
圖14 [5]
Mask R-CNN [7] :CNN + RPN + RoIAlign + FPN [6]
截至目前為止所介紹的R-CNN、Fast R-CNN、Faster R-CNN都是屬於Object Detection的模型,但是R-CNN並不止於此,Mask R-CNN提出了一種概念上簡單、靈活且基於Faster R-CNN的架構,Mask R-CNN在基於Faster R-CNN的基礎上進行了拓展,將原本應用於Object Detection的模型拓展到Instance Segmentation任務上,Instance Segmentation是什麼?

圖15
圖15展示了四種不同的圖像視覺任務: 左上角 : Classification,圖像分類,“氣球” 右上角 : Semantic Segmentation,語義分隔,“氣球的像素” 左下角 : Object Detection,目標檢測,主要是框出目標,“框出氣球的位置並且辨識” 右下角 : Instance Segmentation,實例分隔,不僅要框出氣球所在的位置,還要mask出屬於氣球的像素,“框出氣球的位置並且辨識還要mask出屬於氣球的像素”
為了能夠正確的mask出物體的像素,Mask R-CNN對於Faster R-CNN做出了RoI pooling部分的修正。
在Faster R-CNN中所使用的RoI pooling技術是將proposal feature map粗略分割為H x W 的網格並且對每個子網格做max pooling操作(如圖7),這樣的操作在對於精確度不高的Object Detection任務中足以勝任,但是在Instance Segmentation任務中需要到達像素級別的精確度,因為除了需要框出物體的位置外,還需要將屬於物體的像素點mask出來(如圖15右下角)。
圖7
在Faster R-CNN中,候選框是由: RPN中的anchors經過positive和negative的判斷後,再經過regression修正(此時的候選框座標可能有小數) 由於特徵圖中沒有帶有小數的座標點,所以候選框的座標直接取整數(如圖16)(第一次量化) 執行RoI pooling(如圖7)(第二次量化) 經過兩次量化後位置的資訊已經有所偏移,不足以用來精確的mask出物體所屬的像素點。
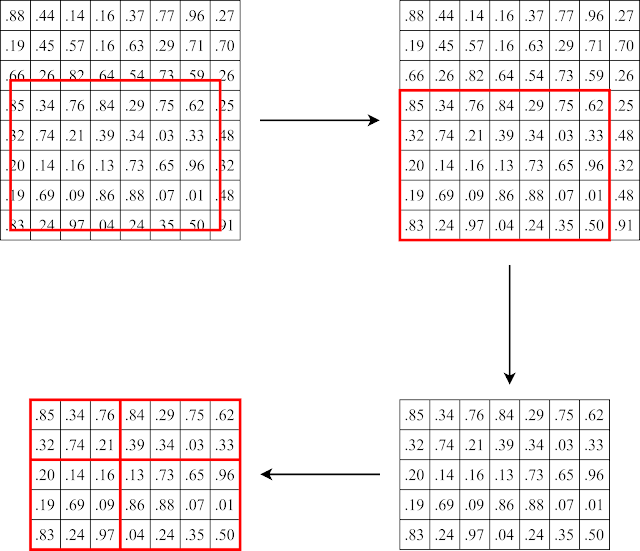
圖16
為了解決這個問題,Mask R-CNN對RoI pooling進行了修改,不再使用取整數的方式來取值。
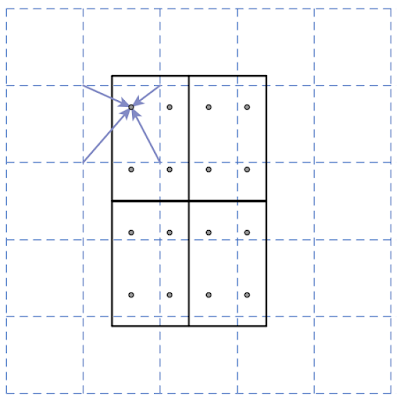
圖17 [7]
為了解決這個問題,Mask R-CNN對RoI pooling進行了修改: RPN中的anchors經過positive和negative的判斷後,再經過regression修正(此時的候選框座標可能有小數) 不對候選框(RoI)的座標取整數(保持有小數狀態) 將RoI直接平分成H x W個網格(bins),並且在每個子網格中平均取4個採樣點,每個採樣點的值由周圍最靠近的4個點做雙線性擦值(bilinear interpolation)取得 子網格的值由子網格內的4個採樣點做max/average pooling而得 在RoIAlign中,所有的值都為帶有小數狀態並沒有經過量化。
Mask R-CNN還新增了一個預測mask的head,mask head可以採用FCN或是FPN模型,由於Mask R-CNN採用FPN作為mask head的結果較好,就介紹以FPN當作mask head的架構。
Mask R-CNN整體架構:
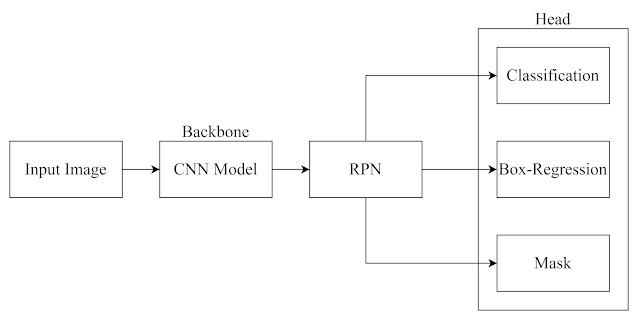
圖18
FPN [6](如圖19)簡單來說就是利用卷積過程中的特徵圖(features map)來對高維度的特徵圖進行upsampling。
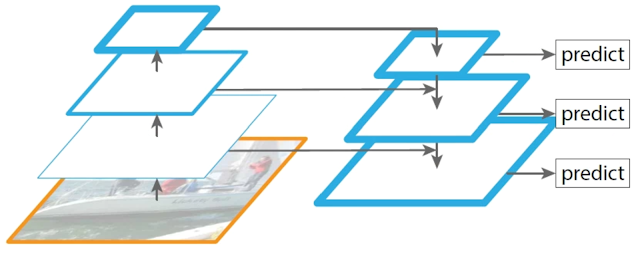
圖19
假設卷積過程中各個階段的特徵圖為C2、C3、C4、C5,FPN的具體操作為: C5經過Conv1-256後成為P5 將P5進行upsampling後與經過Conv1-256後的C4相加後成為P4 將P4進行upsampling後與經過Conv1-256後的C3相加後成為P3 以此類推
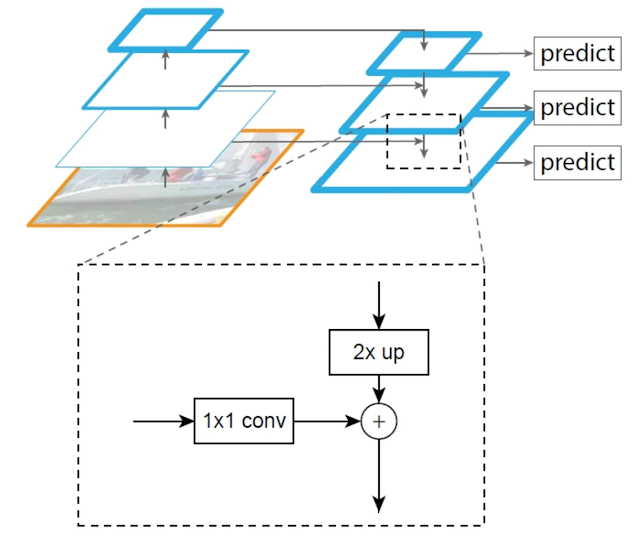
圖20
Mask R-CNN 在目標檢測(Object Detection)上的結果:
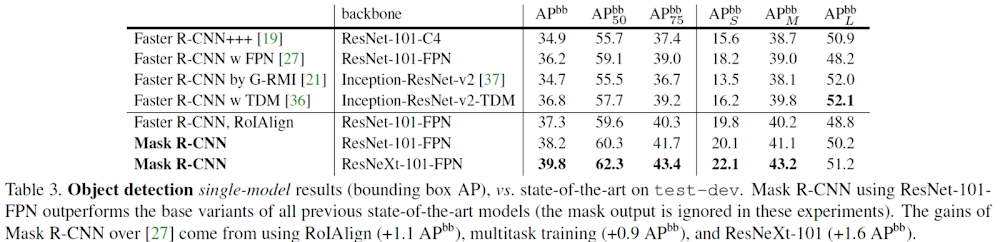
圖21
Mask R-CNN 在實例分割(Instance Segmentation)上的結果:
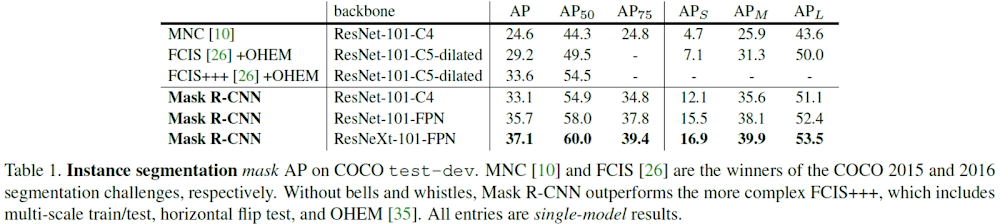
圖22
Mask R-CNN結果:

實作(Implementation)
實作的部分採用matterport/Mask_RCNN [12]展示,由於論文原文 [7]中所公開的實作專案 [13]是採用PyTorch並且在Linux或MacOS平台上所實作的,與我平常習慣的操作系統和深度學習架構不同所以優先介紹matterport/Mask_RCNN [12],未來有機會再補上Linux、PyTorch版本的。
matterport/Mask_RCNN
- Python 3.4
- TensorFlow 1.3
- Keras 2.0.8
- 其他library列在requirements.txt中
在以下環境中成功執行(2020/07/28):
- Python 3.7.5
- TensorFlow 1.15
- Keras 2.1.3
- 其他library列在requirements.txt中
安裝&測試執行流程:
- git clone https://github.com/matterport/Mask_RCNN.git
- 安裝相關library
1pip install -r requirements.txt - 執行setup
1python setup.py install - 從Github上下載test_DEMO.py並且將test_DEMO.py放入專案中
1git clone https://gist.github.com/ghit42796/65965f82b1ada3b4cb47010f95323a42 - 執行test_DEMO.py
1python test_DEMO.py
訓練部分(只在TensorFlow 1中測試過),從Github上下載train_DEMO.py並且將test_DEMO.py放入專案中:
|
|
在TensorFlow2也可以執行只需要將repository改成akTwelve/Mask_RCNN [14]
|
|
其他操作同上
PointRend [8] : TO BE CONTINUED!!
Reference:
- R. Girshick, J.Donahue, T.Darrell, and J.Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. In CVPR, 2014.
- J. Uijlings, K. van de Sande, T. Gevers, and A. Smeulders. Selective search for object recognition. IJCV, 2013.
- R. Girshick. Fast R-CNN. In ICCV, 2015.
- K. He, X. Zhang, S. Ren, and J. Sun. Spatial pyramid pooling in deep convolutional networks for visual recognition. In ECCV. 2014.
- S. Ren, K. He, R. Girshick, and J. Sun. Faster R-CNN: Towards real-time object detection with region proposal networks. In NIPS, 2015.
- T.-Y. Lin, P. Doll´ar, R. Girshick, K. He, B. Hariharan, and S. Belongie. Feature pyramid networks for object detection. In CVPR, 2017.
- Kaiming He, Georgia Gkioxari, Piotr Doll´ar, and Ross Girshick. Mask R-CNN. In ICCV, 2017.
- A. Kirillov, Y. Wu, K. He, and R. Girshick, “Pointrend: Image segmentation as rendering,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020.
- A. Krizhevsky, I. Sutskever, and G. Hinton. Imagenet classification with deep convolutional neural networks. In NIPS, 2012.
- K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. In ICLR, 2015.
- 一文读懂Faster RCNN
- https://github.com/matterport/Mask_RCNN
- https://github.com/facebookresearch/detectron2
- https://github.com/akTwelve/Mask_RCNN